Dijkstra's Prime Number Algorithm
I was reading Tanenbaum’s paper [1] lately, which contains an algorithm for calculating prime numbers attributed to E.W. Dijkstra [2]. What is remarkable about this algorithm is, that it uses no divisions at all! 1 Just a very innocent looking check for inequality is performed to single out divisible numbers.
The algorithm was given as an example for a special purpose language SAL. Here is a literal translation of this algorithm to lua, in its full glory:
local N = 100
local M = 10
function PRIME() -- PROCEDURE DECLARATION;
local X, SQUARE, I, K, LIM, PRIM -- DECLARATION OF VARIABLES;
local P, V = {}, {}
P[1] = 2 -- ASSIGNMENT TO FIRST ELEMENT OF p;
print(2) -- OUTPUT A LINE CONTAINING THE NUMBER 2;
X = 1
LIM = 1
SQUARE = 4
for I = 2, N do -- LOOP. I TAKES ON 2, 3, ... N;
repeat -- STOPS WHEN "UNTIL" CONDITION IS TRUE;
X = X + 2
if SQUARE <= X then
V[LIM] = SQUARE
LIM = LIM + 1
SQUARE = P[LIM] * P[LIM]
end
local K = 2
local PRIM = true
while PRIM and K < LIM do
if V[K] < X then
V[K] = V[K] + P[K]
end
PRIM = X ~= V[K]
K = K + 1
end
until PRIM -- THIS LINE CLOSES THE REPEAT
P[I] = X
print(X)
end
end
PRIME()By running this program, you can quickly verify that it produces a a
list of the first 100 prime numbers. (The 100th prime number is 541,
who would have thought?).
But even after looking at the algorithm for a while, I was not quite
able to make sense out of it. Can you?
A refactored version
Let’s see if we can make this rather acrane program more readable by refactoring it into a form that is more ‘modern’ idiomatic and easier to comprehend. The result is the following listing:

Aside: As you can see, this algorithm also served as the perfect material for testing out my shiny old “Triumph Durabel” typewriter, from the 1940ies.
If you don’t like typewriters, you can have a look a the code on Github. The commit history, shows how you can arrive at this refactored version in 14 simple transformations, that did not change the results of the computation, such as:
- Change variable names.
- Don’t use print statements for output, but return a table.
- Remove iteration indices
IandKby using the#-operator, to get the table size. - Introduce the a function
is_primethat calculates and returns thePRIMflag.
While making these changes the logic of the calculation became more apparent to me. I hope that others might find this version also easier to read.
How does it work?
So, what goes into the workings of this algorithm?
The table P contains the list of already computed prime numbers.
The nuber x is the current active prime candidate, which runs over
the odd numbers. This is fair, since the case P[1] = 2 has been
explicity taken care of. Within the iteration we can assume, that all
primes p < x are listed in P.
To check, that x is prime, we have to check that no number d with
divides x. The following reductions are well known:
- It suffices to check the case
dis a prime number. - It suffices to check numbers .
We call the smallest prime number, that we don’t have to check the
‘limit prime’ q and set . Clearly q be the
smallest prime number such that .
It turns out, that the limit prime q is always smaller than x, and
hence we can find q in our table of already computed prime numbers:
P[q_idx] = q. (I was not able to find a simple proof of this
assertion, but it follows from
Bertrand’s postulate
quite easily.)
Now, the table Q maintains a list of multiples of the primes in P,
which are close to x:
-
We want
Q[k]to be the smallest multiple ofP[k]so thatx <= Q[k]. If the condition is checked and maintained in the line:if x > Q[k] then Q[k] = Q[k] + P[k] endQis kept up to date with every candidate numberxso we need to addP[k]at most once in this step. -
The largest prime we need to check is the one before the limit prime
q, with indexP[q_idx-1].Qonly stores values up to that index.
Hence, by comparing x to Q[k] for equality we can can check if
P[k] divides x. Doing this for k = 2..#Q, gives a sufficient
condition for x being prime, according to the remarks above.
All in all, this algorithm is an interesting mix between the Eratosthenes Sieve (that would maintain a list of all integers up to x), and a naive test of divisibility by primes, up to . Figure 2 contains my humble attempt to visualize (some aspects of) the algorithm for the first few prime numbers.
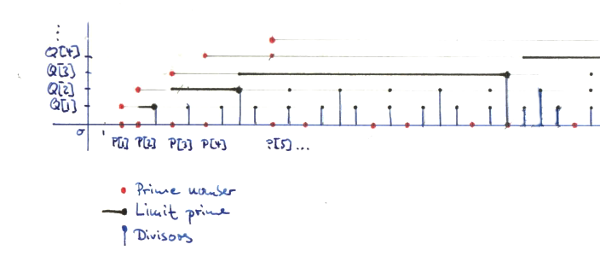
The algorithm is also quite memory efficient. In addition to the list of primes, we only store one integer for each prime up to . There are approximately primes smaller than (cf. Prime-number-theorem). Hence the asymptotic memory requirements are:
Which is the asymptotic size of the result set.
Open Ends
At some point, I’d like to translate this algorithm to a pure functional style, that avoids iteration and local variables and just relies on function arguments and recursion. I hope that in this way to correctness of the algorithm is easy to proof.
Also the visualization has clear room for improvement. Ideally, I’d like to have a dynamic version of this, that updates itself as the algorithm moves along. This will have to wait for another post.
REFERENCES
- A.S. Tanenbaum - General-Purose Macro Processor as a Poor Man’s Compiler-Compiler, IEEE TOSE, Sol.SE-2, No.2, JUNE 1976
- E.W. Dijkstra - Notes on Structured Programming (pdf)
Footnotes
-
As pointed out by amelius on HN the Eratosthenes sieve does not use divisions as well. I still find it remarkable that you can avoid divisions, while not to computing all multiples up-front and marking the results in a large table. ↩